1.结论建议
我从《六壬大全》中的64课体中抽取和九宗门相关的课体,和《大六壬直指》中720课中的课体进行对比统计,我发现排名前四的课体,占了九宗门总频次的81.4%。
这4个九宗门课体及其出现的次数由高到低罗列如下:
| 九宗门 | 出现次数 | 累计次数 | 累计百分比 |
| 贼克 | 329 | 329 | 47.75% |
| 比用 | 100 | 429 | 62.26% |
| 涉害 | 72 | 501 | 72.71% |
| 伏吟 | 60 | 561 | 81.42% |
这是不是意味着九宗门只学前四个就可以了呢?
答案是否定的。我们只能说,掌握了九宗门中的前四个,就相当于学会了一大半。
九宗门不同于64课经,九宗门中每个方法都应当熟练掌握,但是可以不必平均用力。我们可以先重点掌握前四个,后五个简单了解,不必死磕,用到的时候再强化即可。
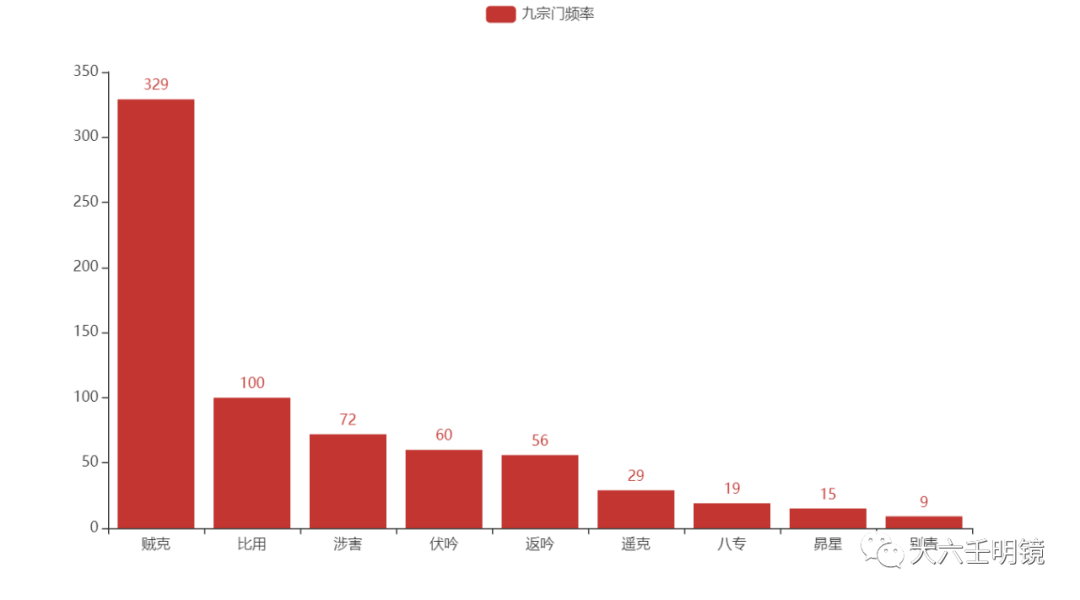
九宗门出现的次数由高到低罗列如下:
| 九宗门 | 出现次数 | 累计次数 | 累计百分比 |
| 贼克 | 329 | 329 | 47.75% |
| 比用 | 100 | 429 | 62.26% |
| 涉害 | 72 | 501 | 72.71% |
| 伏吟 | 60 | 561 | 81.42% |
| 返吟 | 56 | 617 | 89.55% |
| 遥克 | 29 | 646 | 93.76% |
| 八专 | 19 | 665 | 96.52% |
| 昴星 | 15 | 680 | 98.69% |
| 别责 | 9 | 689 | 100.00% |
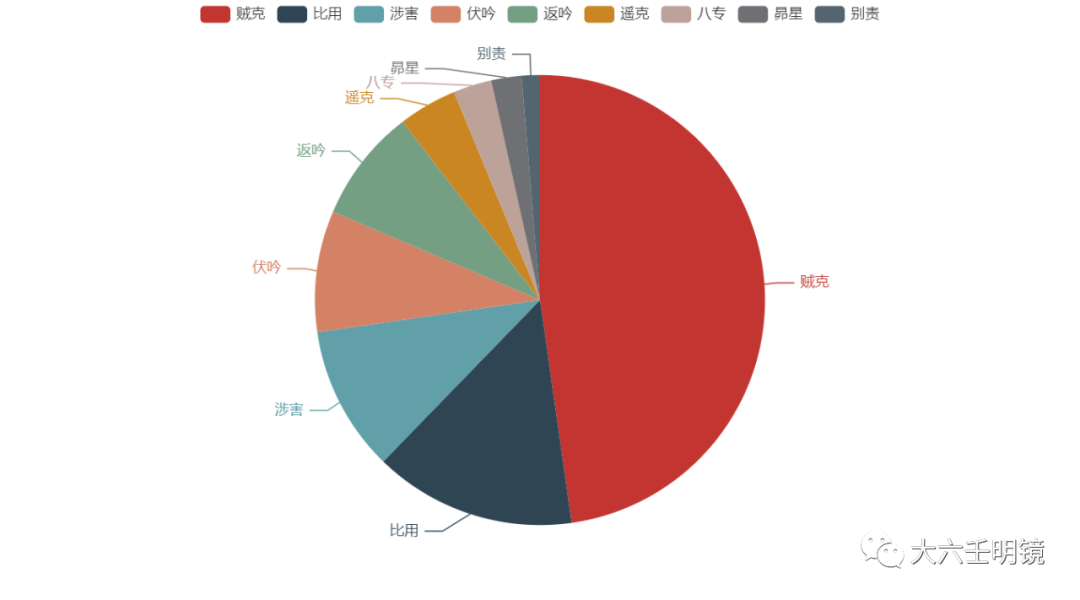
九宗门的柱状图和饼状图如下:
2.思路方法
大体思路是用python中jieba库,用九宗门中的课体,对《大六壬直指》中的文本中的课体进行分词,然后对课体频率进行统计排序。
需要注意的是,《大六壬直指》中其他部分,比如课义,解曰等地方,也会出现部分课体词语,造成统计结果不准确的问题。
我用正则表达式的方法,提取出《大六壬直指》中只包含课体所在的段落,生成新的文本,然后再用此文本进行后续的文本分析工作。需要指出的是,课体的段落有719个,720课中有一课没有课体。
在进行文本分析过程中,有4个课体,jieba库无法识别。我把这六个课体单独提取出来,进行手工统计,然后把统计结果加到语义库中。
经过这两步操作,我们仍然不能确保统计的结果准确无误。
宗门九课中,有贼克和比用两课,六壬直指课体没有直接出现。我把重审和元首归结为贼克课,把知一、度厄、无禄、绝嗣归类为比用课。
其余的七课,六壬直指课体直接出现,为了避免重复统计,此七课直接在六壬直指课体中搜索。
把九宗门拆分开的原始数据统计结果如下:
| 重审 | 213 |
| 元首 | 116 |
| 不备 | 85 |
| 涉害 | 72 |
| 知一 | 71 |
| 伏吟 | 60 |
| 返吟 | 56 |
| 蒿矢 | 37 |
| 遥克 | 29 |
| 弹射 | 25 |
| 度厄 | 22 |
| 八专 | 19 |
| 昂星 | 15 |
| 别责 | 9 |
| 掩目 | 8 |
| 见机 | 6 |
| 察微 | 5 |
| 无禄 | 4 |
| 虎视 | 4 |
| 井栏射 | 3 |
| 绝嗣 | 3 |
在统计的过程中我发现,在六壬直指课体中,一个课体会同时出现多个九宗门,比如涉害和度厄在同一个课体中,却属于涉害和知一两个不同的九宗门。
还存在同一个九宗门课体在一个课体中重复出现,比如:比如知一、度厄都属于比用课,却在同一课体重复出现。
六壬直指的这种课体排列,会导致统计中重复、交错的情况出现。
因此,对于九宗门的统计结果,与实际情况会出现略微差别。但是大体比例以及排序,是没有问题的。
3.实现代码
此代码与上一篇课经统计的差不多:Python文本分析:大六壬课经的学习建议。主要部分是用Python实现的,部分结果由Excel实现,在此放上部分Python代码。
import jiebafill_name = '六壬直指课体.txt'key_name = '九宗门.txt'save_name = '九宗门排序.txt'txt = open(fill_name, encoding="utf-8").read()need_words = open(key_name, encoding="utf-8").read()wordslist = need_words.split()words = jieba.lcut(txt)counts = {} #分词后的词典xx = {'度厄': 22, '蒿矢': 37, '井栏射': 3,'昴星': 16}counts.update(xx) #增加不能识别的单词results = {} #所需关键词的词典for word in words:counts[word] = counts.get(word, 0) + 1lst = [] #不存在的词for i in range(len(wordslist)):try:#print(wordslist[i], counts[wordslist[i]])results[wordslist[i]] = counts[wordslist[i]]except:lst.append(wordslist[i])print('不存在的词:', lst)print(results)
最后和大家说一件事情。
我创建了个知识星球,致力于打造一个整洁、干净、小而美的玄学圈。
公众号的文章无法评论互动,星球的功能很强大,简直就是公众号、扣扣群、微信群、朋友圈的结合体。相比于微信群和朋友圈,星球更加有利于知识的长期沉淀。
我会在星球分享更多的实战卦例以及六壬学习经验。
圈子可以建立主题和标签,方便对圈子内容进行归类。目前有六壬论课、六壬学习、资料分享、学习打卡等标签。后续还可以根据需要扩展。
每个人都可以在对应标签下自由创作,发布图文、视频和文件等内容,每个文章和状态下面都可以自由评论,还可以向圈主和嘉宾提问。
欢迎你的加入。知识星球入口:
大六壬在线排盘大六壬金口诀大六壬入门大六壬排盘六壬神课小六壬——预测须知
大六壬在线排盘大六壬金口诀大六壬入门大六壬排盘六壬神课小六壬Python,文本分析,大六壬,九宗门Python,文本分析,大六壬,九宗门Python,文本分析,大六壬,九宗门
延伸阅读(大六壬、奇门遁甲、法术奇门、阴盘奇门、梅花易数、皇极经世、四柱、六爻、风水、铁板神数、太乙神数、六壬史上最全版古今秘籍汇总|儒释道古本及民间术数大全超强版持续更新中......)

版权声明:本站部分内容由互联网用户自发贡献,文章观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请拨打网站电话或发送邮件至1330763388@qq.com 反馈举报,一经查实,本站将立刻删除。
文章标题:Python文本分析:大六壬九宗门数据统计发布于2023-03-14 15:44:37